Author context: Over ~12 years at Indeed I led product for SMB Analytics and later Employer Analytics & Data, built company-wide metrics and data products, and ran a years-long experimentation program that upskilled product teams.
TL;DR: Keep data work inside product teams. Use a thin platform and light governance guardrails. If you avoid centralizing during growth, data mesh becomes a natural evolution rather than a painful/impossible retrofit. If you want to do ML and AI… you need good data.
How it starts: small teams, short loops
Early on, there’s no central data team. Product engineers and generalists answer questions straight from the product database. The same people ship features and metrics, and have expertise in the whole pipeline. Context is easy, decisions are fast.
How it slows: distance grows with scale
Growth adds teams, handoffs, and process. A central data group looks efficient, but distance creeps in. Requests build up, and bottlenecks start to appear. Unofficial data copies appear. The slowdown is structural, not a talent issue.
Field note — SMB Analytics
- Context: Our most valuable SMB datasets were drifting & unreliable. Teams disagreed on definitions and ownership.
- Move: I pitched a centralized data team to standardize and guard the core sets.
- Result: Short & medium-term clarity & dramatic improvements in reliability & delivery. Over time, as Indeed grew (and the team with it), growing distance from product engineers, and the team found itself putting out fires more often.
- What I’d do now: Staff up data folks & keep them co-located with product teams – create a small central team to focus on platform capability & governance needs.
The inflection point: resist centralizing during growth
Narrator: We missed this at Indeed
As you scale from a few teams to many, it feels natural to centralize data. In my experience, it’s a mistake. If you resist and keep data roles embedded with product engineers, data mesh is a small step later. Centralize first and switching to domain ownership means unwinding org charts, pipelines, and habits – if you can even convince the organization that this is a priority. Doable, but slow and costly.
Why data mesh got popular
Data mesh reframes analytics as an organizational problem. Its four principles are: domain-owned data, data as a product, a self-serve data platform, and federated computational governance. The aim is essentially proximity: shrink distance while keeping consistency. It’s a prescription to scale data at a company – and it’s much easier to put in place vs. switch to it after the fact.
Why mesh retrofits stall
Retrofits fail when you start from a large central team with ticket culture, thin domain ownership, and a fragmented platform. In my experience, data is often the last priority – and dedicating significant effort to unwinding a centralized data team are usually too much for leadership to stomach, given other priorities. See the appendix for more real-world failures… there are many examples of failures to actually switch to data mesh.
Field note — Employer Data & Analytics
- Context: Our data org scaled to ~75 people supporting 10+ fast-moving product areas. Domain context thinned. Upstream schema changes and event drift broke pipelines often.
- Move: I pitched a shift to domain-owned mesh: embed data roles in product teams, and keep the centralized governance and infrastructure teams as-is.
- Result: Leadership agreed in principle, but revenue-priority work usually won. We were also able to use high-profile metrics, like Connections, as vehicles for data mesh principles to great effect. With some motivated teams, we were able to move data & product engineering closer to one another and show meaningful success. However, we were not able to drive the paradigm change we wanted.
- What I’d do now: Double-down on the teams that we saw success with and publicize more broadly, and focus on nailing 2-3 of the most important data products.
AI and why companies care deeply about this
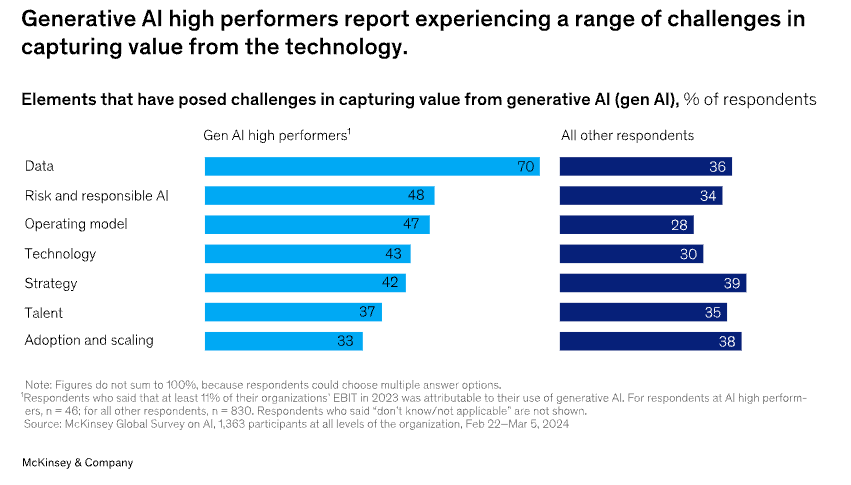
Here’s an amazing stat – Gen-AI adoption jumped in 2024 to 65% of organizations using it regularly in at least one function. However, two-thirds of data leaders said they were not completely confident in the quality of the data powering AI.
Even among high performers integrating Gen-AI, 70% say they have experienced difficulties with data, including defining processes for data governance, developing the ability to quickly integrate data into AI models, and an insufficient amount of training data, highlighting the essential role that data play in capturing value. Companies that effectively integrate Gen-AI say that the data is far and away their biggest challenge.
Call to action for growing startups, small to medium tech companies, etc.
You are near the inflection point… Do not centralize analytics. If you get this right today, you save years of rework later. I’ve lived both sides – learn from my mistakes. Instead:
- Build a central platform. Self-serve ingestion, transformation, CI for SQL, observability, lineage.
- Publish a thin semantic and governance layer. Shared definitions, ownership metadata, PII rules, versioning.
- Embed data talent with product engineering. Analysts and data engineers sit with the teams they serve, and begin defining & prioritizing the most important data domains.
Commit to one domain this quarter. Name the metric you will move and the data product you will own.
Appendix
Data mesh failure modes, with real examples
- Paused midstream due to governance gaps. One large enterprise halted its mesh rollout when it could not harmonize data management practices or agree what to centralize vs keep in domains. Business users reverted to old workflows. Remedy was executive sponsorship and formal change management tied to business value. McKinsey & Company
- Low domain talent density. Many attempts stall when domains lack skilled owners. Overlapping product needs, tiny data orgs, and fragmented platforms create churn. Fix by staffing domain owners, clarifying shared products, and consolidating platform services. Monte Carlo Data
- Scaling too fast. Teams try to roll mesh to every domain at once. Thoughtworks reports this as the top failure driver and advises a slow start with two or three data products over about six months. Thoughtworks
- Proxy mesh. Central teams continue acting as proxies for domains, which preserves distance and spawns shadow teams. Shift real ownership and budgets to domains and make the platform self-serve. Nextdata
- Culture and business ownership missing. Implementations fail when mesh is treated as tech only. Reports cite lack of buy-in and data fluency, plus weak business ownership of data products. Put business leaders on the hook for accuracy and SLAs. MediumMedium
- Anecdotal but telling. Practitioners have shared failed, all-in mesh programs that “crashed and burned,” often due to unclear goals and weak ownership. Treat anecdotes carefully, but the pattern matches the issues above. Reddit

Leave a comment